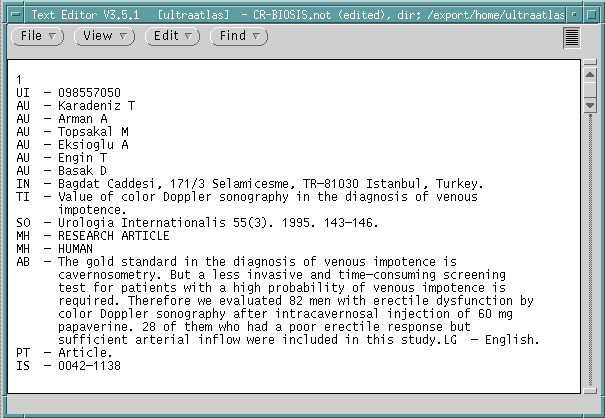
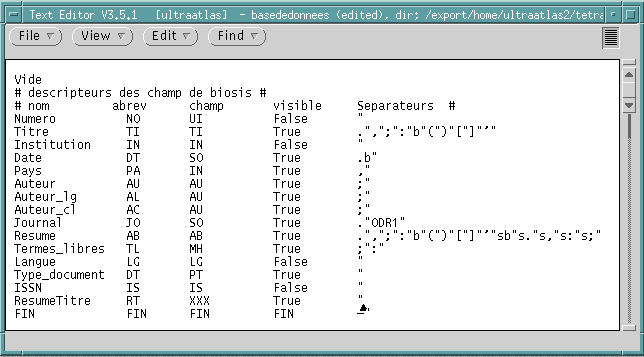
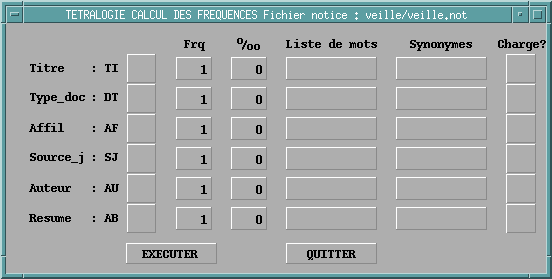
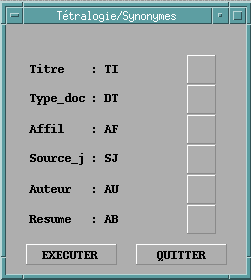
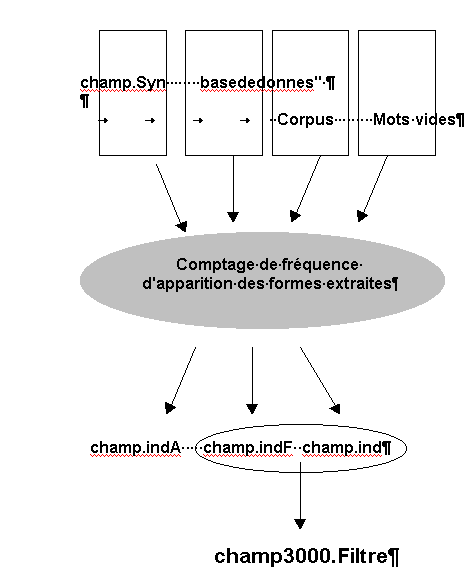
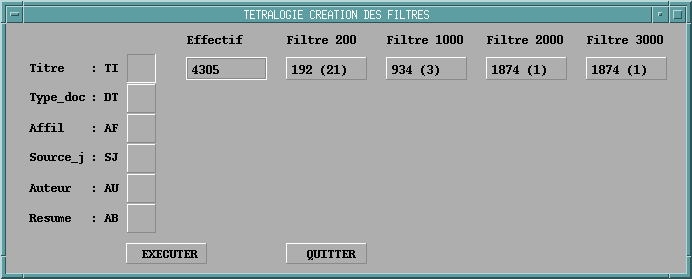
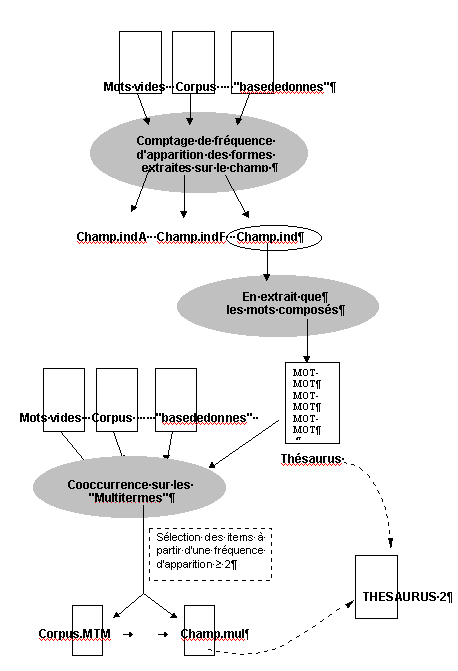
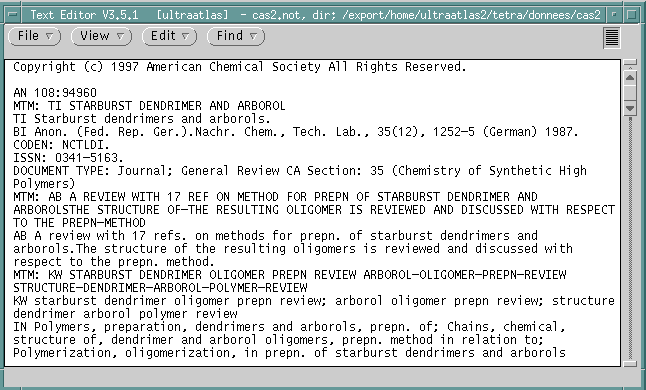
|
Ce
que vous observez
|
Méthode
|
|
-
Opération n°1 :
Vous
n'obtenez pas des groupes homogènes le long de la diagonale
par un simple tri de connexité ou de bloc :
|
-
Transformation en divisant les cellules par la racine carrée
des marginales,
-
Multiplication par au moins 100 ou 1000 de tout le tableau,
-
Erosion à partir d'un seuil de 2 et plus si nécessaire,
-
Tri de connexité (vous pouvez rediriger le résultat
du tri de connexité en lançant Tétralogie
> fichier, vous pourrez ainsi visualiser les groupes de mots).
N'oubliez pas de sortir de Tétralogie.
|
|
-
Opération n°2 :
La
première opération a peu de résultat
|
-
Choisir de préférence des tris par blocs plutôt
que des tris de connexité.
|
|
-
Opération n°3 :
J'obtiens
des groupes vers le bas de ma diagonale mais le reste est toujours
lié :
|
Procéder
de façon récursive :
-
Isoler la partie toujours liée en la sauvegardant sous
un autre nom,
-
Utiliser la méthode n°1 en augmentant le seuil progressivement
et à chaque itération ne garder que la partie non
triée.
|
|
Quelques
soient les tris toutes mes informations sont liées
|
Regardez
le synonymage et vérifiez vos filtres ainsi que le Thésaurus
créé. Il doit y avoir une erreur quelque part. Avez-vous
pensé au seuil d'érosion ?
|
|
J'ai
fait une AFC, ai-je besoin de triér mes données
?
|
Non,
l'AFC et l'ACP s'observent d'elles-mêmes. Par contre, pour
vérifier les résultats, il est intéressant
de trier récursivement en utilisant les outils mis à
votre disposition.
|